
Designing Institutional Data Capture for Quantitative Research.
Payload to Disk.

Hello folks, I’ve spent the couple of months working on quantpylib, and the bulk of the refactor has been done~ I am excited to start doing up the docs so our users can experiment with it. As early as next week!
One of the revamped subsystems was the improvement of data capture architecture towards more institutional grade archival policies. This article will be dedicated to describing what may constitute such a change.
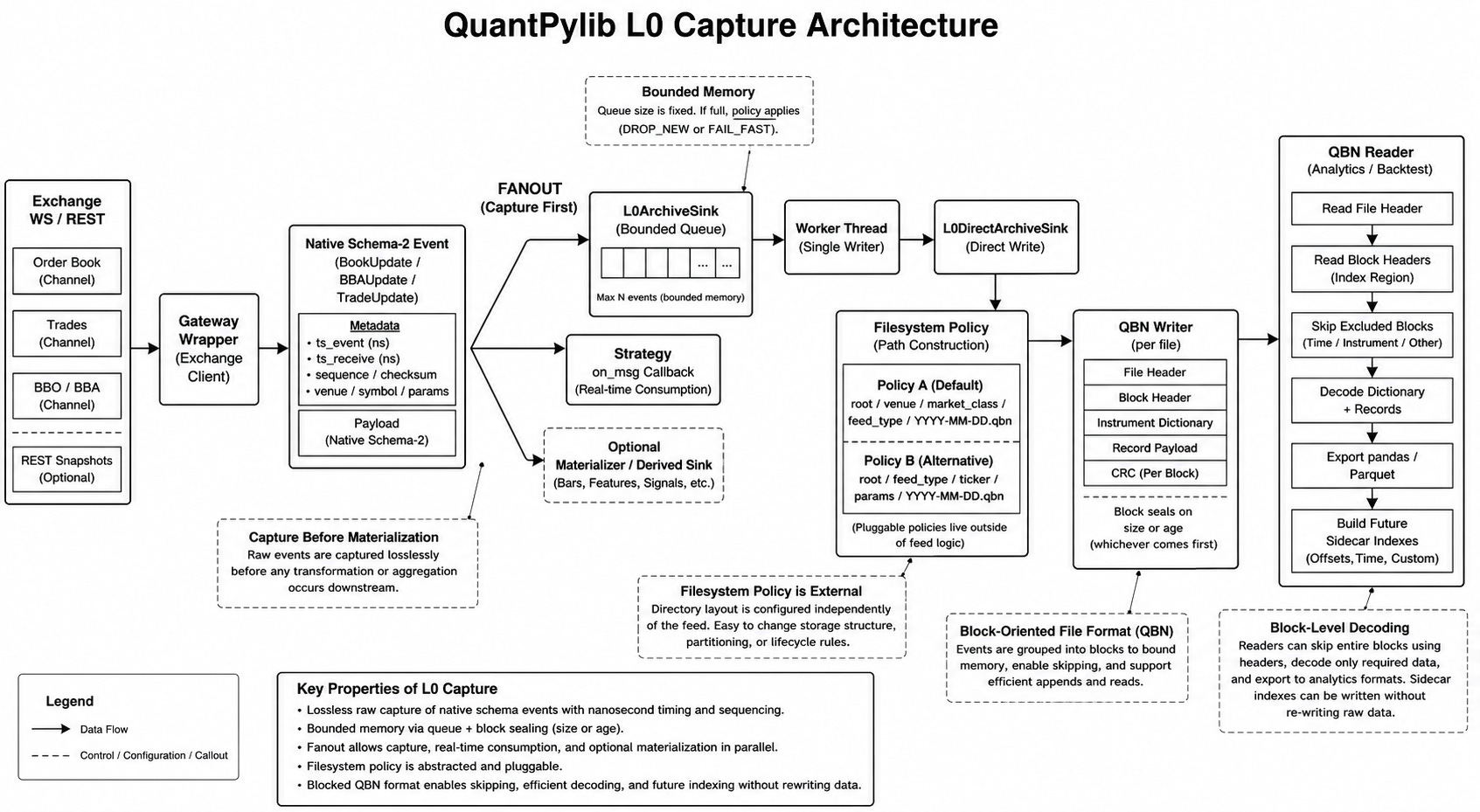
Modern quantitative research is becoming less constrained by storage cost and more constrained by the quality of the artefacts we choose to preserve. Cheap cloud object stores, high-throughput local disks, and increasingly capable agents have changed the economics of retention. It is now cheaper to store, easier to dig, making data storage policies and approach correctness a step-change more important as an interface for humans and intelligent solutions to sift through valuable insights hidden in the data.
For a trading desk, the highest-value artefacts are the operational record: market data, order traces, fills, gateway logs, replay journals, risk decisions, and the metadata that ties these streams together. Agents are good at sifting, ranking, joining, and summarising. But they are only as useful as the substrate underneath them.