Intrusive Design for Low-Latency Trading Systems
intrusive design, intrusive pointers and gotchas

In the last post we covered low-latency logging design by adapting a cache-friendly disruptor buffer to byte sequences and exploiting compile-time eval of static log data.
As promised, the next series covers fast message parsing and orderbook implementations. Once done, our hft repo will have covered spsc queues, fast instrumentation and feed ingest. Not bad progress I think.

Before we go into the orderbook series, I thought I would just introduce a design (anti)pattern that works in low-latency systems. While general programming and design principles are well-heeded, hft patterns often adopt antipatterns for performance over [some-other-tradeoff]. Consider the busy-wait pattern over condition variables, for instance. The tradeoff is of-course wasted cpu cycles.
An intrusive data structure/container is one where the management associated with the contained item is in the data item itself. This flies against the separation of concerns. A list of PhoneBookAddress should not require that each PhoneBookAddress is list-aware.
This pattern is not restricted to queues, lists and what-not. One place where intrusive design can surface is smart-pointers. We will do a dive into intrusive pointers in this post, and similar analysis applies to this design pattern on other containers in performance critical code.
Let’s start with the very basics.
RAII Primer: Foundation of Safe Memory Management
Resource Acquisition Is Initialization (RAII) is the bedrock of modern C++ memory safety. The idea is simple: tie resource lifetime to object scope. When an object goes out of scope, its destructor automatically releases the resource - no manual delete calls, no forgotten frees and memory leaks that crash your program.
Scott Meyers of Effective Modern C++ tells us why its hard to love raw pointers:

Shared Pointers: RAII for Shared Ownership
Enter std::shared_ptr, the standard library RAII solution for shared ownership. It lets multiple owners share an object, automatically deleting it when the last reference vanishes. Under the hood, it uses reference counting: each copy increments a count, each destruction decrements it, and zero triggers deletion.
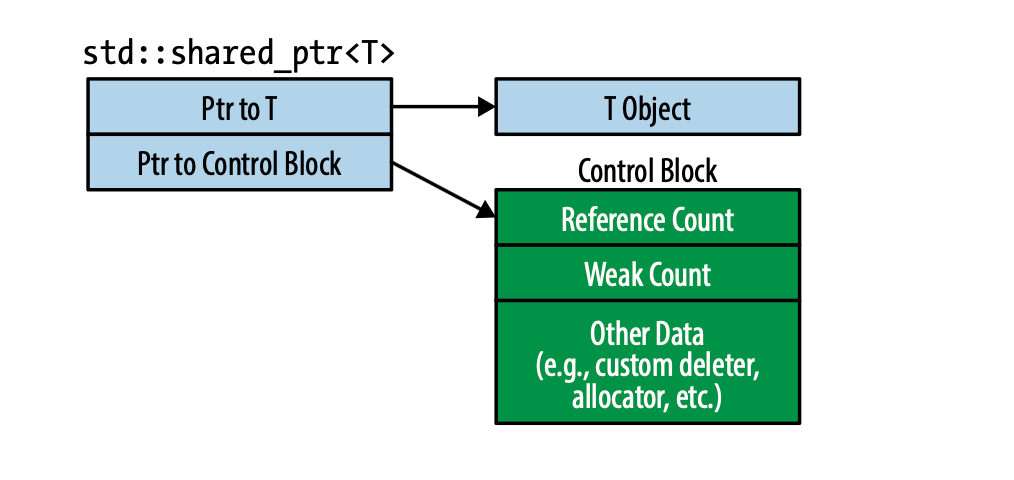
This is not a free lunch. The shared pointer object has to do the proper accounting. The object itself is typically two words wide, one pointer to your object and another to a control block. This block, dynamically allocated on the heap, holds:
An atomic reference count for thread-safe increments/decrements (using std::atomic or equivalent, which introduces synchronization overhead).
A weak reference count (for std::weak_ptr support).
Type-erased allocator/deleter (via virtual dispatch or function objects), allowing custom deletion logic but adding indirection.
We therefore pay heap allocation jitter, possible cache misses (the control block and object may not be in contiguous memory blocks) and atomic count operations. Notably, unless we are guaranteed that the object is only to be accessed by a single thread, the atomics are inevitable (unless you want to do some locking). It would be however be nice if we can choose the thread safety semantics.
std::make_shared
A partial optimization makes up for some of the costs associated with the control block. C++11’s std::make_shared optimizes by allocating the object and control block in one contiguous heap chunk. This reduces allocations (one instead of two), improves cache locality, and shrinks the footprint.
auto ptr = std::make_shared<TradeOrder>(); // Single allocation!Intrusive Pointers: zero-cost abstractions
Intrusive here means the reference count lives inside the object, not in a separate block. We must modify TradeOrder to include the count. We can make use of static polymorphism and the CRTP (Curiously Recurring Template Pattern) so that a class is intrusively aware of its shared owners. We will not go into the CRTP pattern and template metaprogramming here, GPT-that.
Boost gives us boost::intrusive_ref_counter templates that support this pattern along with configurability for thread-safety (optional atomics!) and the boost::intrusive_ptr container that uses compile-time magic without vtable overheads at destruction:
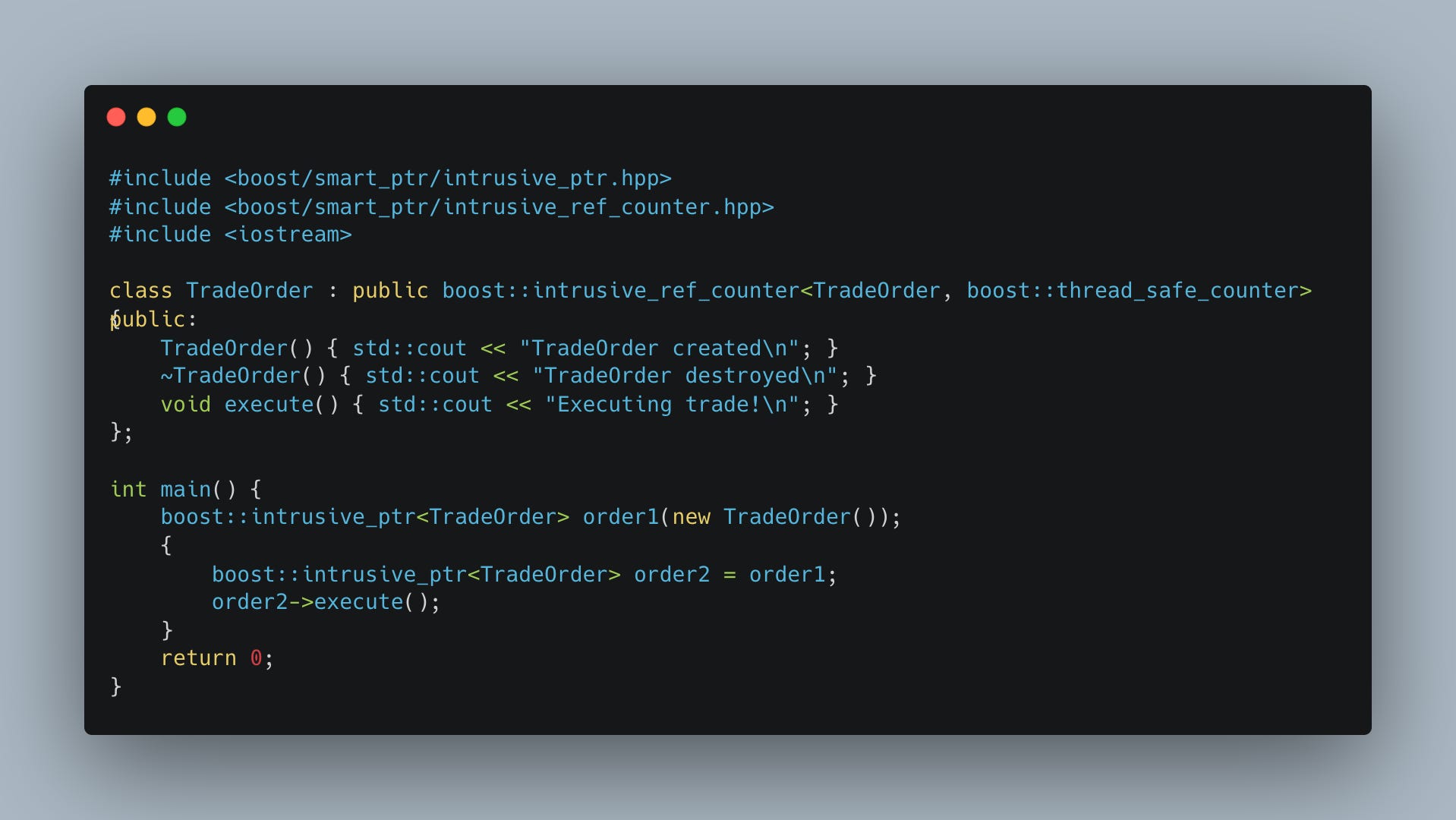
No control blocks are allocated meaning that there is no separate heap allocation. Further, the reference counts sit on the same cache line as the data members, and cache locality means better l1-hit rates. Memory footprints are minimal and the destructor is known at compile-time, no type erasures and vtable lookups.
Similar cost-benefit analysis applies to data structures. For instance a common L3 design of the orderbook uses doubly linked list to contain orders for each limit price. Often for performance reasons, this data-structure is intrusively designed. We will explore some of these in the future posts.
Anyhow, smart pointers are smart, but humans are stupid, so let me round up the post with some gotchas on intrusive pointers. These are not specific to intrusive pointers per se, and apply to shared ownership semantics. The points are not performance-related.
Gotchas
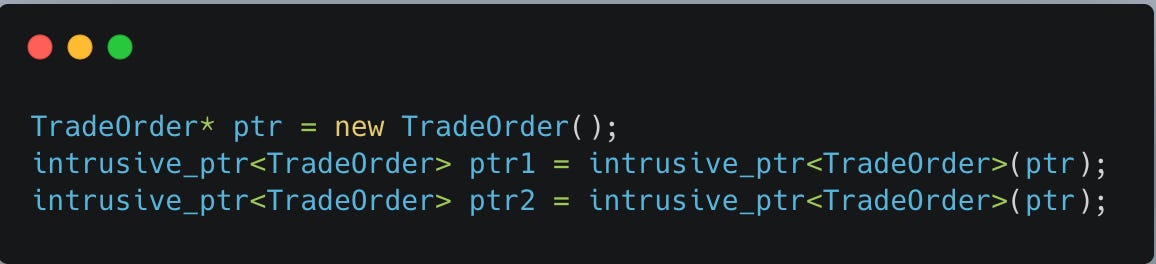
If you are going to construct an intrusive_ptr, use new in the argument list to avoid separate control blocks/reference counts. Consider the following:
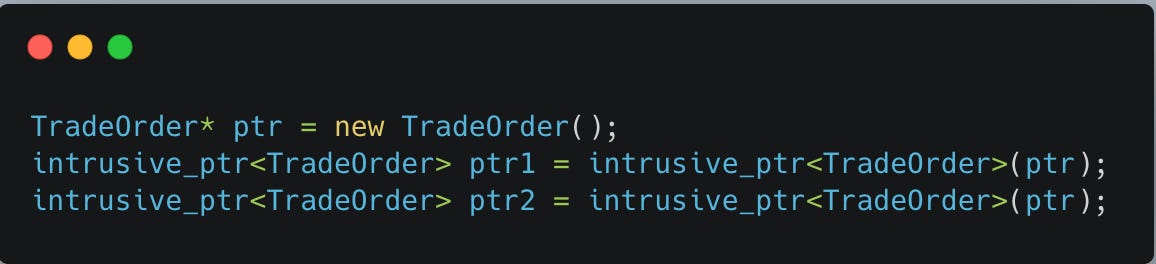
This is pretty dire, now two intrusive_ptr objects keep separate reference counts without knowledge of the other. When they destruct, double free and we are in UB zone. Something like this prevents us from monkey business.

Perhaps there is a reason why make_unique and make_shared exists. Not only does it mean we don’t make stupid mistakes (see point 1), we can also make subtle mistakes. Consider:

Compiler only asserts that arguments of functions are evaluated before the function call (duh) but not in the order of evaluation of the arguments themselves. The TradeOrder malloc is performed before the call to intrusive_ptr. Now a troubling sequence:
heap alloc for TradeOrder
call throwable func, which, throws
intrusive_ptr never get’s ownership, makeMoney more like loseMemory
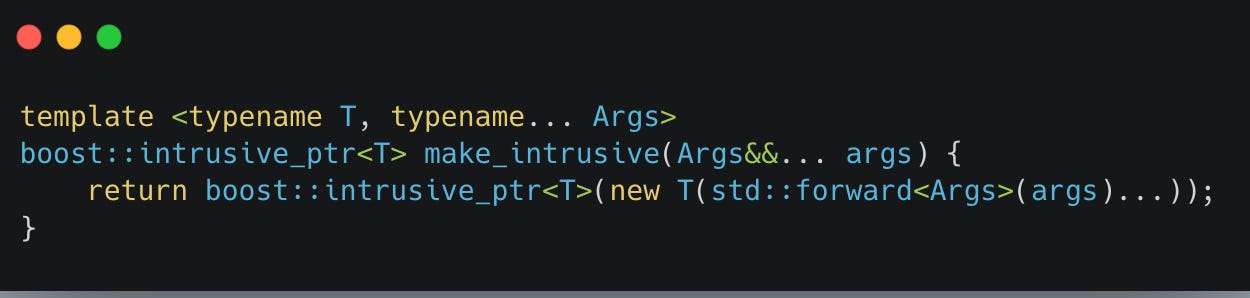
Thankfully we can unclench our butt with our very own helper functions with perfect-forwarding semantics:
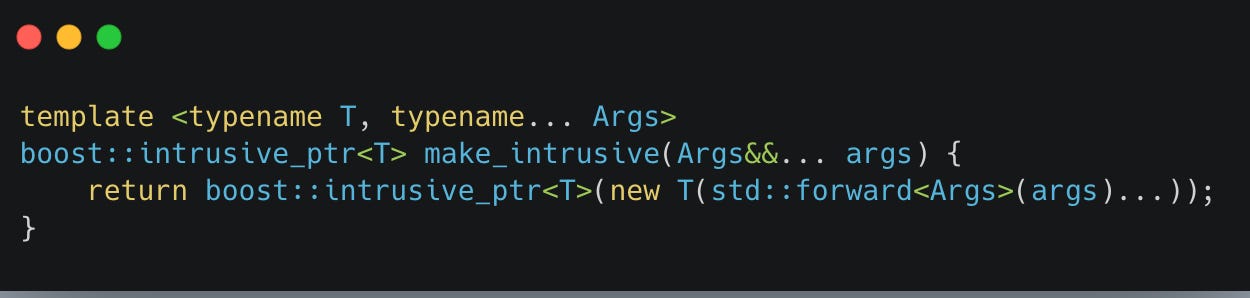
Happy (low-latency?) trading!