Performant Logging (Introduction)
Designing state-of-the art, performant logging frameworks. Comparing four logging implementations.

This marks the first of a series of articles on designing SOTA logging frameworks suitable for HFT. We will explore four different implementations in this series. This post introduces the ‘logging problem’ and formalises problem context of instrumentation under tight latency requirements.
Future posts cover these implementations, compare latencies and implements an optimal logging framework.
This post is sponsored by Autonity - introducing…
Exclusive Alpha Access: Autonity's Forecastathon
HangukQuant subscribers get early access and team formation priority Autonity's Autonomous Futures Protocol (AFP) is live on Bakerloo testnet. Create and trade forecast futures on real-world data US jobless claims, GDP, inflation.
The Forecastathon: Launching September The Forecastathon is a play-money trading competition for dated futures contracts that settle on measures such as inflation rates, unemployment figures, climate, etc. Build and test predictive models and trading strategies in a competitive market for real rewards.
Team Formation Week (to be announced soon)
Create or join a team during the formation period
Both individual AND team leaderboards run simultaneously
No downside to team participation, only additional rewards All challengers will trade forecast futures using simulated capital.
Exclusive HangukQuant Access Access Code: OQM2DV7A0231
First 100 users only - expires in 1 week
Quick Start:
Redeem code: https://app.autonity.org/invite
Test AFP: https://proto-afp.pages.dev/trade
Join Discord for setup: https://discord.com/channels/753937111781998605/963812274181664799
Python SDK: https://pypi.org/project/afp-sdk/
Problem Context
In systems such as low-latency trading applications where target latency is <1-10 μs, naive logging solutions are prohibitively costly. The typical approach to cull logs is not a particularly tempting one, since logs are crucial part of instrumentation and observability of running processes.
It is well known that performing I/O operations on the hot path is to be avoided, since IO introduces unpredictable stalls from syscalls, kernel buffering, context switches, and device latency. Any synchronous path to disk or sockets can blow through the latency budgets by orders of magnitude and spike latency variance.
Typically, low-latency systems decouple the act of recording a log event from the act of persisting it. This is typically achieved through in-memory staging structures such as lock-free ring buffers or single-producer/single-consumer queues, where the hot path registers logging data.
The actual string formatting and emission to disk, network, or telemetry systems is offloaded to background threads, which can tolerate higher variance in service times without disturbing the critical path.
While these problems are well known (that string formatting and emissions are to be offloaded), the how and specifics matter.
Four Implementations
We will explore four implementations, in order of performance (of my own impl)
naive, print logging 1000ns~
logging impl from Building Low Latency Applications with C++, building low latency trading…. 500ns~
closure-based logging impl, thread sync through spsc disruptor…5~200ns
compile-time metaprogramming and sync through spsc disruptor… 5~25ns
Before comparing solutions, the word better performance is a contentious statement. What do we mean by better? Obviously, this depends on problem context.
Under low-latency trading contexts, this often is latency, but even this is a bit handwave-y. I realised I have been throwing around ‘performance’ figures with some abandonment, so let me clear the air on this, with lessons taught to me by @xoreax_eaxeax on X.
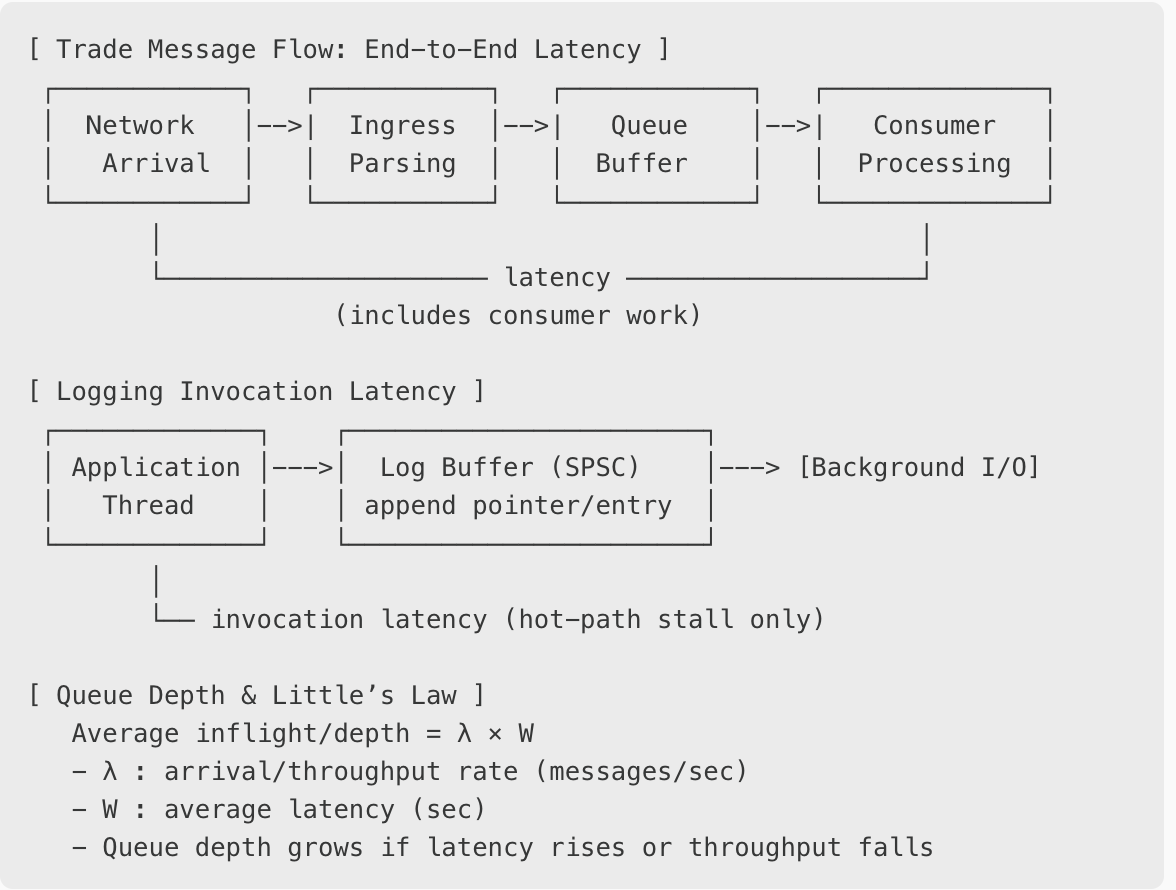
The primary figure of interest (on the system) is the end-to-end latency: the time from when a market data tick or trade message arrives on the wire until the consumer has fully processed it. This includes not just transport (time to be put on/off the queue) and queuing delay (time spent in the queue waiting to be consumed), but also the consumer’s own work.
By contrast, for subsystems like logging, what matters most on the hot path is the invocation latency: how long a producer thread is delayed when it issues a log call - this affects the e2e latency. Whether the background thread takes milliseconds or seconds to flush to disk is largely irrelevant, provided the staging buffers do not overflow and we don’t encounter back-pressure issues.
[ Trade Message Flow: End-to-End Latency ]
┌────────────┐ ┌───────────┐ ┌────────────┐ ┌──────────────┐
│ Network │-->| Ingress │-->| Queue │-->| Consumer │
│ Arrival │ │ Parsing │ │ Buffer │ │ Processing │
└────────────┘ └───────────┘ └────────────┘ └──────────────┘
│ │
└───────────────────── latency ───────────────────┘
(includes consumer work)
[ Logging Invocation Latency ]
┌─────────────┐ ┌───────────────────────┐
│ Application │--->│ Log Buffer (SPSC) │---> [Background I/O]
│ Thread │ │ append pointer/entry │
└─────────────┘ └───────────────────────┘
│
└── invocation latency (hot-path stall only)
[ Queue Depth & Little’s Law ]
Average inflight/depth = λ × W
- λ : arrival/throughput rate (messages/sec)
- W : average latency (sec)
- Queue depth grows if latency rises or throughput fallsOn a related concept, throughput is the steady-state rate at which a system can accept and process messages. For applications like media-streaming, file downloads - this metric is important. We can think of it constrained by the slowest stage in the pipeline. No matter how fast other components are, the maximum sustainable rate is the bottleneck’s capacity. Latency on the other hand is additive across the various concerned processing stages.
Their relation is governed by Little’s Law (see above) - average latency is inversely proportional to the throughput, and scaled by the queue depth. Since consumers poll items off the queue sequentially in FIFO order, when an item is placed on the queue, and has significant queue depth, it’s latency incurs significant queueing delay, and the inverse relationship between throughput and latency diverges by a factor of this depth at steady-state.
For trading systems designed as asynchronous messaging systems between threads, queue depth is important for objects we need to process with gateway actions (typically what is time-sensitive) in the action-dependency graph. The ability to handle bursty message rates make tail latency distributions critical.
For other paths, invocation latency is important, but queue depth is important only in relation to MAX_BUFFER_SIZE (assume bounded queues), so that producers are wait-free. This is typically not an issue for temporally sparse workloads.
I’ll write a separate post on things I’ve learned about proper latency benchmarking, seriously follow @xoreax_eaxeax! For now, we will keep it to logging.
Now that we have covered what is problematic in logging, and what is important in logging to get right, the next post will go directly into four implementations and compare solutions for logging.
We will discuss
cpp lambdas and closures, small buffer optimization
using the disruptor impl to write a logging event processor.
cache conscious design
using template (meta)programming for cpp logging
adapting the disruptor ringbuffer to a bytebuffer to synchronise batch claims over contiguous byte array.
See our discussion on disruptor: