Performant Logging II. Exploring Lambdas
Lambdas, Closures, Closure Classes in cpp. Notes on compiler SBO, SSO.

In the previous article, we explored the concerns of logging - what is problematic and what is important (invocation latency) in designing performant solutions for logging.

In this post, we dive into one such solution using closures that handle both the log formatting and IO ops. The discussion will take deep look at appreciating cpp lambda-s (the expression), closure (the runtime object of the closure class), as well as neat compiler’s optimization features and what triggers runtime allocation.
For the Rust-ies, you may be interested in: https://markrbest.github.io/fast-logging-in-rust/
Lambda
We look at the anatomy of lambdas. A lambda expression is the syntactic sugar

This instructs the compiler to generate a unique, unnamed class type behind the scenes. Their syntax has the form:
[c-list](p-list) m-sp exc-sp -> return-type { body }c-list: the capture list specifies what external variables the lambda "closes over" from the enclosing scope,
p-list: the arg list specifies arguments passed when invoking the lambda,
the mutable and exception specifiers are optional. mutable makes the captured variables non-const,
body: is the executable code which carries arbitrary logic (i.e. formatting/IO in logging)
This lambda expression is evaluated at compile time - the compiler generates the closure type/closure class i.e. it is subject to aggressive compiler optimizations.
Semantically, we can treat them as anonymous structs generated by the compiler that behaves as a functor with the overloaded operator() function. Let’s take an example -
Closure
Consider

The compiler generates something like the following;
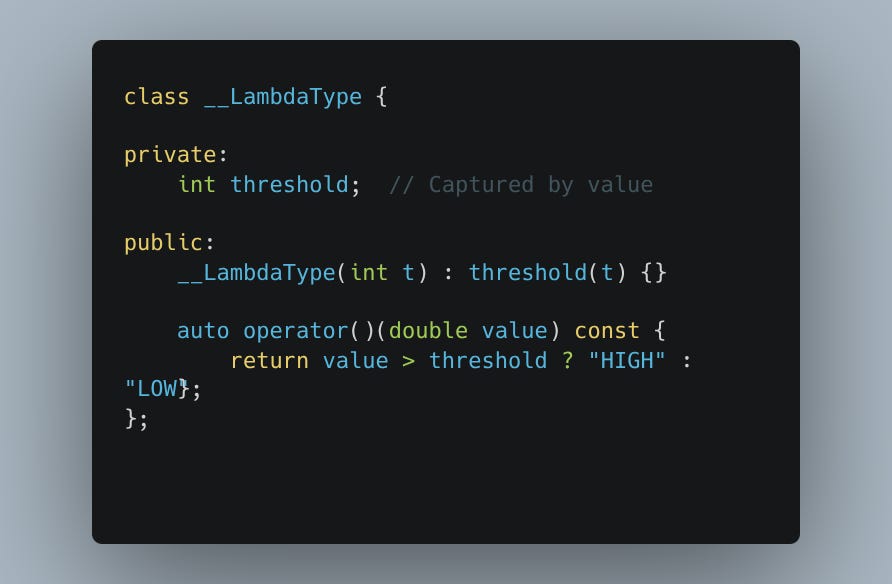
The logger object instance is the closure, and __LambdaType is the closure class.
If we understand these nuances, we are halfway to appreciating the invocation latency of a closure-based logging solution.
Capture
Capture semantics are what gives lambda-s their power; without which they would cease to be more than stateless functors. cpp(14+) exposes 3 capture modes, namely value, reference and init capture.
capture value [=], [x]: this copes all (or the variable x into the closure object. This means that the closure owns its own copy, and lifetime of captured variables is tied to the closure. This avoids dangling references, unless of course the captured variable is a copied pointer. In member functions, [=] implicitly captures this, hence member variables in the function body are only safe up to lifetime of the current object.
capture reference [&], [&x]: Binds a reference member, zero-cost but risks lifetime issues (dangling refs if the closure outlives the capture source).
init-capture [x = std::move(some_string)]: To the left of the =, x is the data member in the scope of the closure class the compiler generates, and on the right, is the initializing expression that is defined in the same scope where the lambda is being defined.
To demonstrate unsafe-behavior, consider the above behavior - if [&threshold] is used in the capture and logger(1) is invoked anywhere outside the local scope where the lambda is defined, this is UB, since __LambdaType holds reference to garbage.
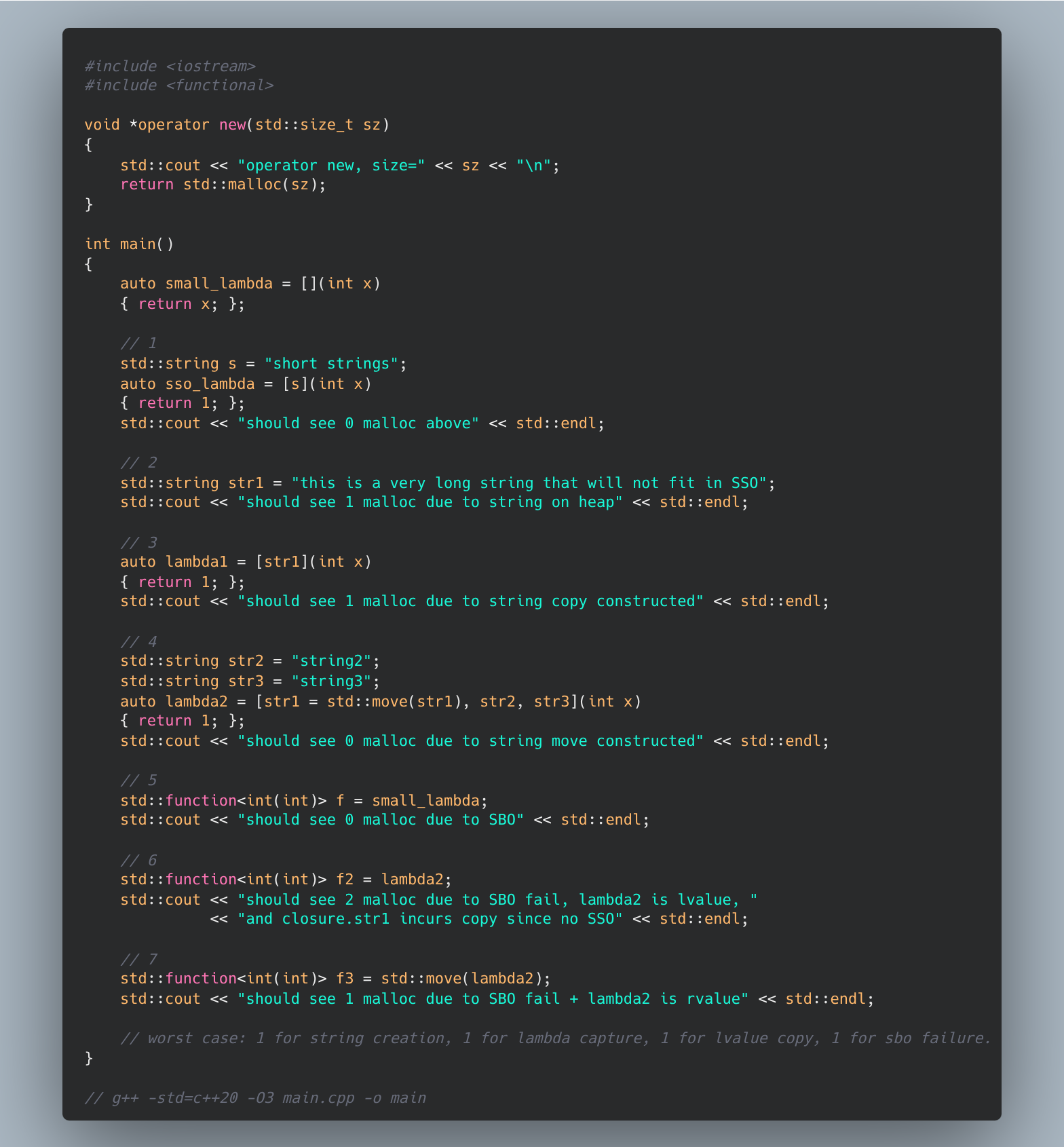
When logging in the hot path, there is motivation to prevent copy-costs in the constructing the runtime closure. The cost of capture is significant in the latency of closure-logging implementations. Where string-s are copied, heap allocations occur (if they do not qualify for Small-String-Optimizations).
Where move-semantics are used, it is up to the developer to ensure no lifetime issues are created.
Type Erasure and the Small Buffer Optimization
This is where things get some what funky…
In order for producers of log records to communicate with consumers, a common mechanism is a single-producer single-consumer (SPSC) queue. Such a queue is typically a lock-free ring buffer that accepts elements of a fixed type T, known at compile time.
However, each lambda expression produces a unique closure type, known only to the compiler:
auto lamb = [](int x) { return x + 1; }; //T cannot be decltype(auto)!We cannot let T the decltype(auto) here because otherwise, two different log messages (closures) cannot be enqueue-d onto the same data structure. To work around this, we apply type erasure. Instead of storing the closure type itself, we store an abstracted wrapper such as std::function<R(Args...)>. This wrapper hides the concrete closure type behind a fixed interface.
But this is not without cost - std::function call requires an extra level of indirection compared to invoking a raw closure. This is minor but still on hot paths. Notably, closure-classes are not the same size! Imagine closure class capturing one int (a thin struct wrapping around int) vs capturing many arguments (struct with many members).
To manage this variability, compilers typically employ a Small Buffer Optimization (SBO) for std::function
If the closure fits within an internal fixed-size buffer, it is stored directly inside the std::function object, avoiding heap allocation.
If the closure exceeds that threshold, allocates on the heap and stores a pointer to the closure.
An aside is that if this say, in this expression, std::function… f = lamb, the closure is an lvalue, then the assignment performs COPIES, memberwise and possibly heap-allocating! Now, I don’t know why such a logging closure would be a lvalue, but just saying…
To really hammer these examples home, I’ve 7(!!) code snippets. Let’s check out these compiler optimizations. We don’t even need to read assembly, thank god, we just make the compiler call our new on heap allocations. In our worst example, there are 4!! heap allocations, and this can be considerably worse.
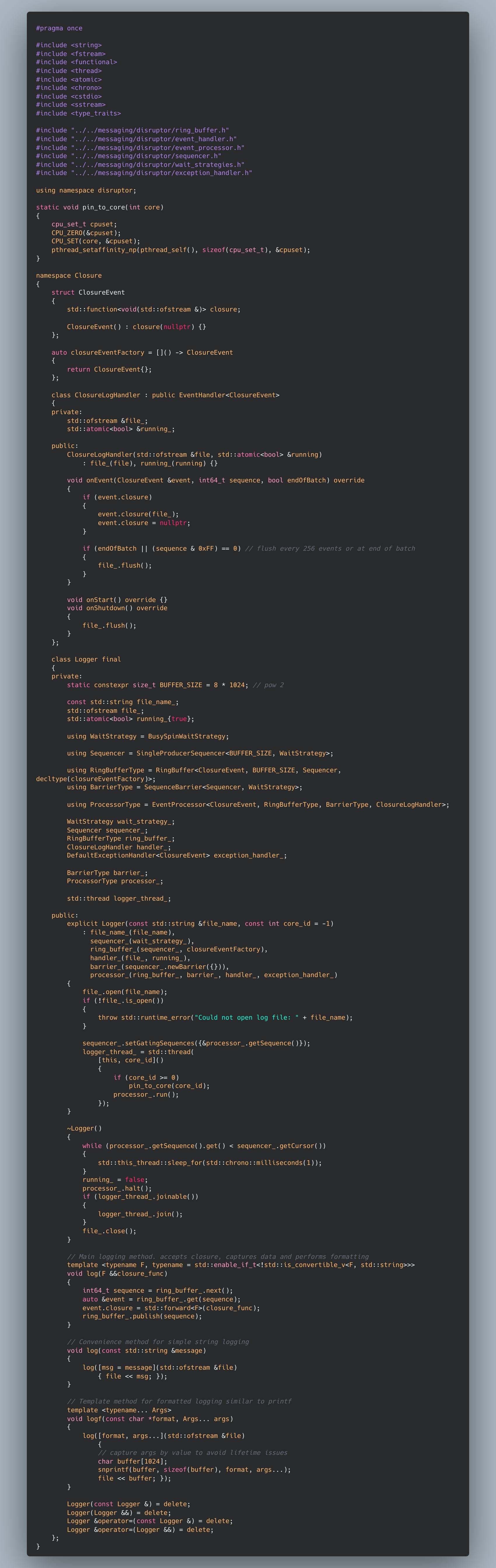
The technical details of closure-logging is now, closed. We’ve already done the hard work of implementing an performant spsc queue using the disruptor pattern:

(see our open source implementation here)
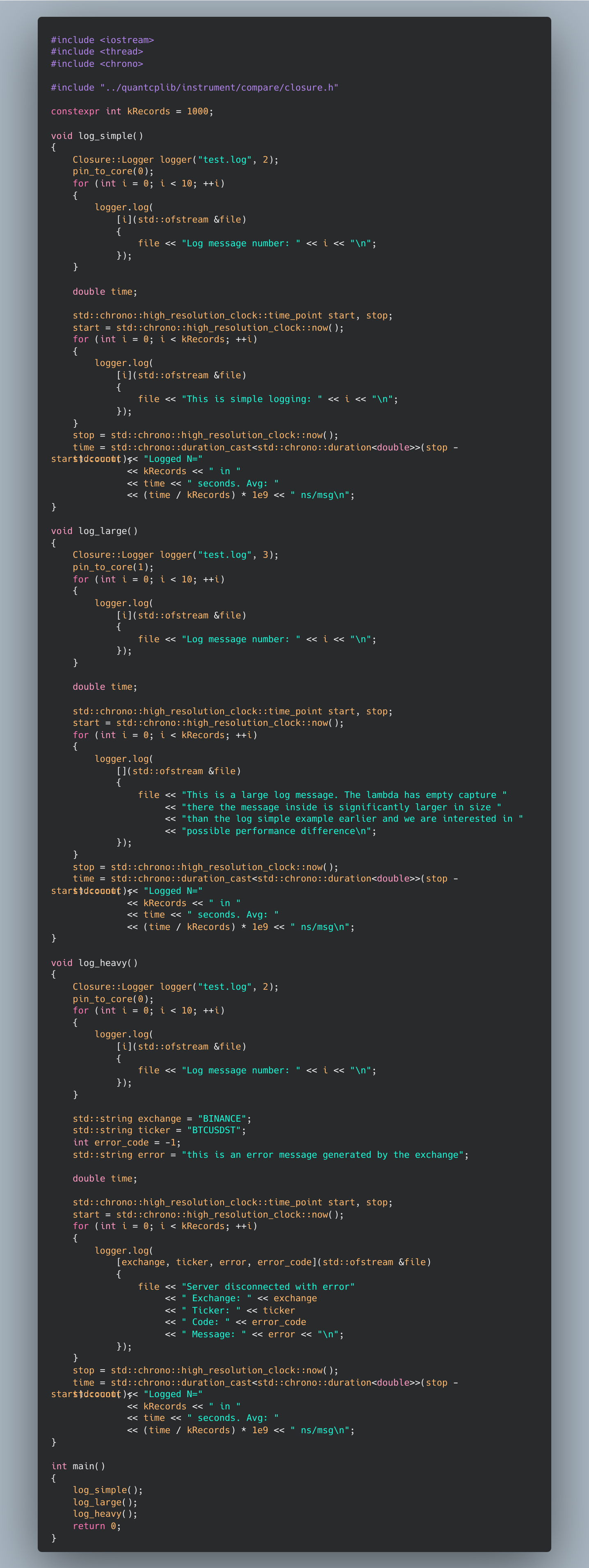
All we have left to do is to write an event processor, and the compiler does the rest of the heavy lifting. I’ve written a simple log processor that uses the disruptor implementation above. See code in the bottom of post…
Using such a logger, a sample logging script measures the throughput of 3 log message types: simple capture, heavy capture. An additional example, log_large shows that the closure size is independent of the body - and is highly performant - we know this since the body is just code in the .rodata and not part of capture. I got the following results
Logged N=1000 in 5.11e-06 seconds. Avg: 5.11 ns/msg (simple capture)
Logged N=1000 in 1.33e-06 seconds. Avg: 1.33 ns/msg (no capture)
Logged N=1000 in 9.0828e-05 seconds. Avg: 90.828 ns/msg (heavy capture)
Before we go into the code, here’s the advertisement for the next post: zero alloc logging! Okay, here’s the code…
Code
Barring the pristine-ness (lack thereof) of the benchmark (i.e. chrono jitter, optimal conditions), these examples clearly show an apples comparison of what impacts invocation latency in the closure-based logger.
A logger thread running event processor to log from spsc queue. With multiple threads, we would need to de-multiplex from thread local staging buffers, but more on that in the next post…Note the use of perfect forwarding to maintain l/r value reference-ness. disruptor implementation is in the github link above.